POOLED TIME SERIES OF CROSS SECTIONS
by François Nielsen & Gary Gaddy
1. Heterogeneity Bias
Techniques of pooled time series of cross sections
are applicable in situations in which one has observations on N units (such
as individuals, areal units, or countries) at T points in time (such as
monthly, yearly, or every 5 years).
With data like these the standard linear regression
model is written:
(1) Yit = a
+ Xit'b
+ eit
with i = 1,...,N; t = 1,...,T
where
a is the
intercept
vector Xit' contains K regressors
for unit i at time t
vector b
contains K regression coefficients to be estimated
by assumption E{eit}
= 0 and Var{eit}
= se2
There need not be the same number of time
points for each unit of observation, but assume T is the same for all units
in this presentation to keep the notation simple.
A main strength of longitudinal design is that
it allows controlling for heterogeneity bias due to the confounding
effect of time-invariant variables omitted from the regression model.
EXAMPLE: A sample of N secondary
school students are observed from the 7th to 12th grades (T = 1,..,6).
Suppose a researcher estimates the model
(2) GPAit = a
+ b1SESit
+ eit
But the "true" model is
(3) GPAit = a
+ b1SESit
+ b2IQit
+ eit
Assume also that SES and IQ are correlated, that
is r(SES, IQ) <> 0.
Then model (2) suffers from specification
bias: the effect of SES is (typically) overestimated.
With longitudinal data, the effect of relatively
time-invariant variables (like IQ in the previous example) will be similar
to the effect of a unit-specific intercept, that varies across units but
remains constant for a given unit over time. If there is such a unit-specific
intercept and it is not included in the regression model, the result is
heterogeneity bias. Heterogeneity bias may cause the OLS estimates
of the parameters to be entirely different from what they are in the "true"
model. The mechanism is illustrated in the next exhibit.
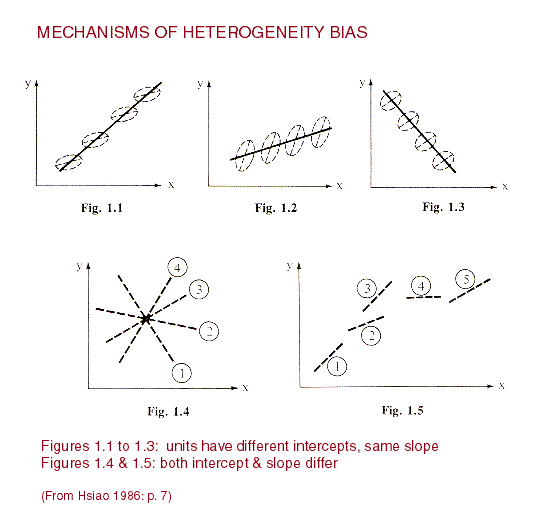
Exhibit: Mechanism
of heterogeneity bias (Hsiao 1986, Figures 1.1 to 1.5 p. 7)
Longitudinal data permit correcting for the
effect of any combination of omitted variables, like IQ, that are stable
over the period of observation. This is done by "simulating" the
combined effect of such time-invariant omitted variables by individual-specific
intercepts ai.
Model (1) becomes:
(4) Yit = ai
+ Xit'b
+ eit
with i = 1,...,N; t = 1,...,T
The individual-specific intercepts ai
capture any combination of time-invariant variables that have been omitted,
knowingly or not, from the regression model.
There are two approaches to estimation of
model (4), the fixed effects model (FEM) and the random effects
model (REM).
2. Fixed Effects Model (FEM)
In the FEM, the ai
(also called incidental parameters) are treated as fixed constants,
as the regression coefficients ai
in the equivalent model:
(5) Yit = a1d1it
+ a2d2it
+ ... + Xit'b
+ eit
where each djit
is a unit-specific indicator (dummy) variable which is 1 when i = j and
0 otherwise. There are N djit
indicators, one for each unit is the analysis. (5) does not include
a general intercept a
to avoid perfect collinearity with the set of N indicators djit
. For the obvious reason, (5) is often called the LSDV (Least Squares
with Dummy Variables) model.
Rather than estimating (5) with N indicators,
the LSDV estimate of b, bLSDV,
can be obtained from an OLS regression of (Yit - Yi.)
on (Xit - Xi.) with no constant term,
where
Yi. is the unit-specific
mean of Yit
Xi. is the vector of unit-specific
means of the predictors Xit
In other words Model (5) is equivalent to an OLS
regression using the deviations of all the variables from their unit-specific
means. This regression is sometimes called the within regression.
The unit-specific intercepts ai
can then be estimated as
ai
= Yi. - Xi.'bLSDV
3. Random Effects Model (REM)
The random effects model is
(6) Yit = a
+ Xit'b
+ ui + eit
with assumptions
E {ui}= 0 and Var{ui}
= su2
Cov{eit,
ui} = 0
Var{eit
+ ui} = se2
+ su2
= s2
Corr{eit
+ ui, eis
+ ui} = r
= su2/(se2
+ su2)
(Note that (6) includes a general intercept a.
Perfect collinearity is avoided by the assumption that the expectation
of the unit-specific errors ui is zero.)
The unit-specific components are now denoted
ui (instead of ai)
to emphasize that they are now considered a stochastic (random) component
of the same type as the error eit,
with a certain distribution characterized by its mean and variance, rather
than fixed parameters.
Note that the assumptions about Model (6) imply
that the variance-covariance matrix of the composite error term (ui
+ eit)
is not scalar, as assumed for OLS, so that OLS is not the best estimator.
Model (6) can be estimated by Generalized Least Squares (GLS). Assuming
that the variance-covariance matrix of the error term is known, say s2W,
the GLS estimator becomes
bGLS = (X'W-1X)-1X'W-1Y
where W-1
is the inverse of the matrix W.
It can be shown that the GLS estimate associated
with the REM boils down to an OLS regression of
Yit - qYi.
on
(1 - q)
and (Xit - qXi.)
where (1 - q)
corresponds to the constant term and q
is between 0 and 1. In other words, the original data are transformed
by removing a fraction q
of the unit-specific means Yi. and Xi., instead
of removing all of the unit-specific means, as the LSDV transformation
does. (In fact the FEM implemented as LSDV can be viewed as a limiting
case of GLS, where q
= 1.)
q is calculated
as
q = 1 -
se/s2
where
s22
= se
+ Tsu2
To estimate q
one must estimate se
and su2.
There are several ways of doing this. (One of the ways is to use
the residuals from the LSDV regression; another uses the OLS residuals.)
4. FEM versus REM
There are several considerations involved in choosing
between FEM and REM:
1. The fixed effects and random effects
approaches can be contrasted by comparing the data transformations with
which they are equivalent.
-
the FEM LSDV transformation consists of removing
the unit-specific means Yi. and Xi. entirely from
the original data.
-
the REM GLS transformation consists in removing
only a fraction q
(where q is
less than 1) of the unit-specific means.
Therefore, the REM transformation may be seen
as preserving more of the information (between units variation) in the
data than the FEM transformation. The GLS transformation is more
efficient than the LSDV transformation, when REM assumptions are
satisfied.
2. The consistency of REM, however, depends
on assumption that the ui are uncorrelated with regressors in
the model. If they are correlated, the estimates are inconsistent.
FEM does not require the assumption that the ai
are uncorrelated with the other regressors, since the ai
are treated as the coefficients of ordinary indicator (dummy) variables
that are allowed to covary with other regressors. While the assumption
of non-correlation for REM may seem restrictive, it is often no more implausible
than the usual assumption that the error term
is uncorrelated with the regressors in ordinary regression models.
In small samples the net result of the trade-off
of efficiency versus consistency is not easy to derive analytically, so
that some of the literature on this topic has used Monte Carlo simulation
to examine the small sample properties of the alternative estimators.
The GLS approach is often found to perform better overall.
In some situations, such as models with the
lagged value of the dependent variable, the ui are necessarily
correlated with one of the regressors. In such cases REM is not justified.
3. FEM uses up all between units variation
and therefore does not allow including time-invariant variables in the
model, as these are collinear with the (explicit or implicit) set of unit-specific
indicators representing the fixed effects. The REM model permits
the use of time-invariant variables.
4. Two statistical can be used in the
context of panel regresion.
-
the Lagrange test compares the REM or FEM versus
OLS; a significant p-value favors REM or FEM over OLS
-
the Hausman test compares REM versus FEM; a significant
p-value favors FEM over REM
5. MODELS INCLUDING TIME-SPECIFIC FACTORS
The previous models can be extended by allowing
for a time-specific component in addition to the unit-specific component.
The FEM version of the time-specific component
model is
(7) Yit = a
+ ai
+ lt
+ Xit'b
+ eit
In model (7) the ai
and the lt
are constrained to sum up to 0.
The REM version of the model is
(8) Yit = a
+ Xit'b
+ ui + wt + eit
The estimation methods are derived in similar
ways.
It is also possible to mix FEM and REM by
using explicit indicators for the time component, say, and the REM for
the unit-specific component, or vice-versa.
6. EXAMPLES
1. Example - Income Inequality and Economic
Development
Exhibit: Title page
of Nielsen & Alderson (1995) with Kuznets curve (Figure 1)
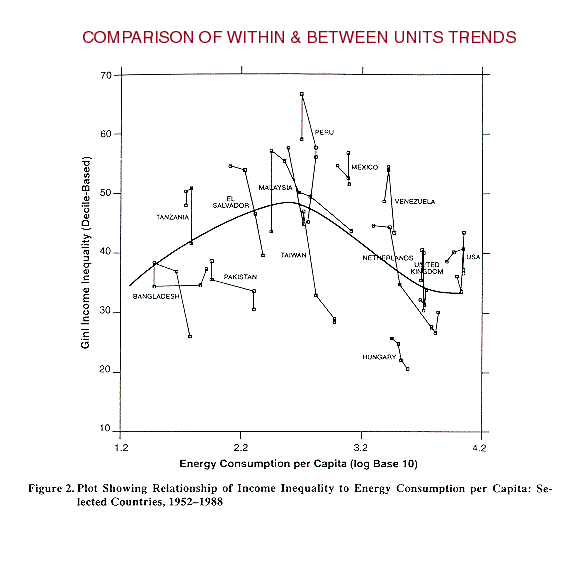
Exhibit: Depiction
of between versus within country inequality trends (Figure 2)
Exhibit: LIMDEP
program
Exhibit: LIMDEP output
for model of income inequality
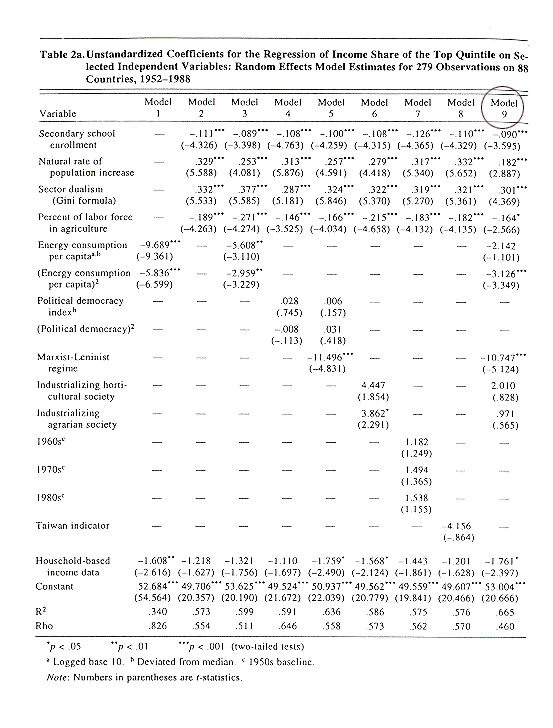
Exhibit: Published
table with model of income inequality (Table 2a)
Exhibit: Joint testing
of groups of variables using OLS (Appendix A)
2. Example - Infant Mortality in European
Countries
<This example is not available at this time>
3. Example - Dynamic Model of Educational
Enrollments
<This example is not available at this time>
7. READINGS
We don't know of any "easy" introduction to pooled
time series of cross sections analysis. You may find that Rosenfeld
and Nielsen (1984) is the closest thing to it. We find Chapter 29
"Fixed and Random Effects Linear Models" in the LIMDEP 6.0 manual very
helpful (Greene, 1992). A more detailed theoretical discussion of
the statistical issues involved can be found in the text by the same author
(Greene, 1990: Chapter 16, especially the section called "Longitudinal
Data" pp. 480-505). Another clear exposition is provided in Judge
et al. (1980: Chapter 8, pp. 325-373; there is a newer edition of this
text). Hsiao (1986) is advanced but difficult. The same may
be said for Tuma and Hannan (1984: Chapter 13). The new book by Baltagi
(1995) is very useful too, and very advanced. Early examples of applications
in sociology can be found in Nielsen and Hannan (1977), Nielsen (1980,
1986), and Pampel and Williamson (1988). See Nielsen and Alderson
(1995) for an application to an unbalanced cross national data set with
different numbers of observations over time for different countries.
Betz and Katz (1995) have recently criticized several studies, mainly in
political science, that use a pooling model called the Parks method, which
was provided as an option in the old SAS TSCSREG procedure, as reporting
unrealistically small standard errors of estimates and exaggerating the
significance of coefficient estimates. Their criticism is specific
to the Parks method and does not apply to methods discussed in this workshop,
however.
8. REFERENCES
Baltagi, Badi H. 1995. Econometric
Analysis of Panel Data. New York: Wiley.
Beck, Nathaniel and Jonathan N. Katz.
1995. "What To Do (and Not To Do) with Time-Series Cross-Section
Data." American Political Science Review 89:634-47.
Greene, William H. 1990. Econometric
Analysis. New York: MacMillan.
Greene, William H. 1992. LIMDEP
User's Guide. New York: Econometric Software.
Hannan, Michael T. and Alice A. Young.
1977. "Estimation in Panel Models: Resulta on Pooling Cross-sections
and Time-series." Pp. 52-83 in David R. Heise (ed.), Sociological
Methodology 1977. San Francisco: Jossey-Bass.
Hsiao, Cheng. 1986. Analysis of
Panel Data. New York: Cambridge University Press.
Janoski, Thomas and Alexander Hicks.
1994. The Comparative Political Economy of the Welfare State.
New York: Cambridge University Press.
Judge, George G., William E. Griffiths, R.
Carter Hill, and Tsoung-Chao Lee. 1980. The Theory and Practice
of Econometrics. New York: Wiley.
Kessler, Ronald C. and David F. Greenberg.
1981. Linear Panel Analysis: Models of Quantitative Change.
New York: Wiley.
Markus, Gregory B. 1979. Analyzing
Panel Data. (Sage University Paper series on Quantitative Applications
in the Social Sciences, 07-018). Beverly Hills, CA: Sage.
Menard, Scott. 1991. Longitudinal
Research. (Sage University Paper series on Quantitative Applications
in the Social Sciences, 07-076). Beverly Hills, CA: Sage.
Mundlak, Y. 1978. "On the Pooling
of Time Series and Cross Section Data." Econometrica 46:69-85.
Nielsen, François. 1980.
"The Flemish Movement in Belgium after World War II: A Dynamic Analysis."
American Sociological Review 45:76-94.
Nielsen, François. 1986.
"Structural Conduciveness and Ethnic Mobilization: The Flemish Movement
in Belgium." Pp. 173-198 in Susan Olzak and Joane Nagel (eds.), Competitive
Ethnic Relations. New York: Academic Press.
Nielsen, François and Michael T. Hannan.
1977. "The Expansion of National Educational Systems: Tests of a
Population Ecology Model." American Sociological Review 42:479-90.
Nielsen, François and Arthur S. Alderson.
1995. "Income Inequality, Development, and Dualism: Results from
an Unbalanced Cross-National Panel." American Sociological Review
60:674-701.
Pampel, Fred and J. Williamson. 1988.
"Welfare Spending in Advanced Industrial Democracies, 1950-1980."
American Journal of Sociology 93:1424-56.
Rosenfeld, Rachel A. and François Nielsen.
1984. "Inequality and Careers: A Dynamic Model of Socioeconomic Achievement."
Sociological Methods and Research 12:279-321.
Sayrs, Lois W. 1989. Pooled Time
Series Analysis. (Sage University Paper series on Quantitative Applications
in the Social Sciences, 07-070). Beverly Hills, CA: Sage.
SAS Institute Inc. 1988. SAS/ETS
User's Guide. (Version 6. First Edition.) Cary, NC: SAS
Institute Inc.
Tuma, Nancy Brandon and Michael T. Hannan.
1984. Social Dynamics: Models & Methods. New York: Academic
Press.
Last modified 24 March 1999
{kind=link}
{kind=link}
{kind=link}
{kind=link}